Word Counter Vault
![]()
An interactive intelligence dashboard and automated reporting tool built to analyze linguistic patterns and global etymology. This project transforms raw text input into actionable forensic insights using a modern Python stack.
🎥 Project Walkthrough
Note: Click the badge above to view the full feature walkthrough and linguistic analysis demo on LinkedIn.
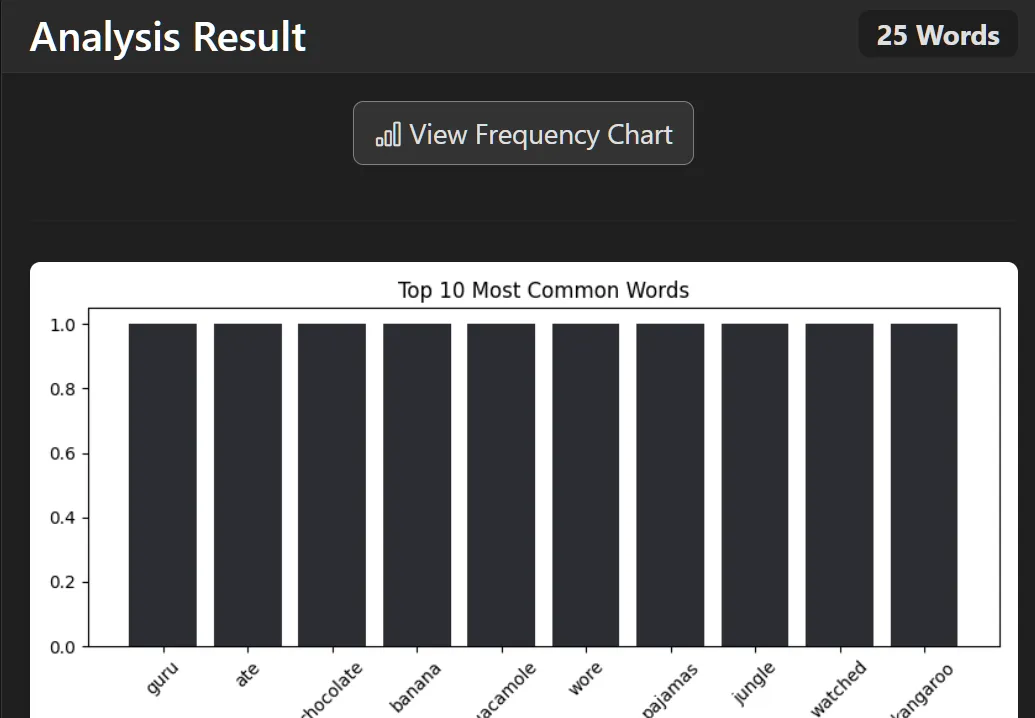
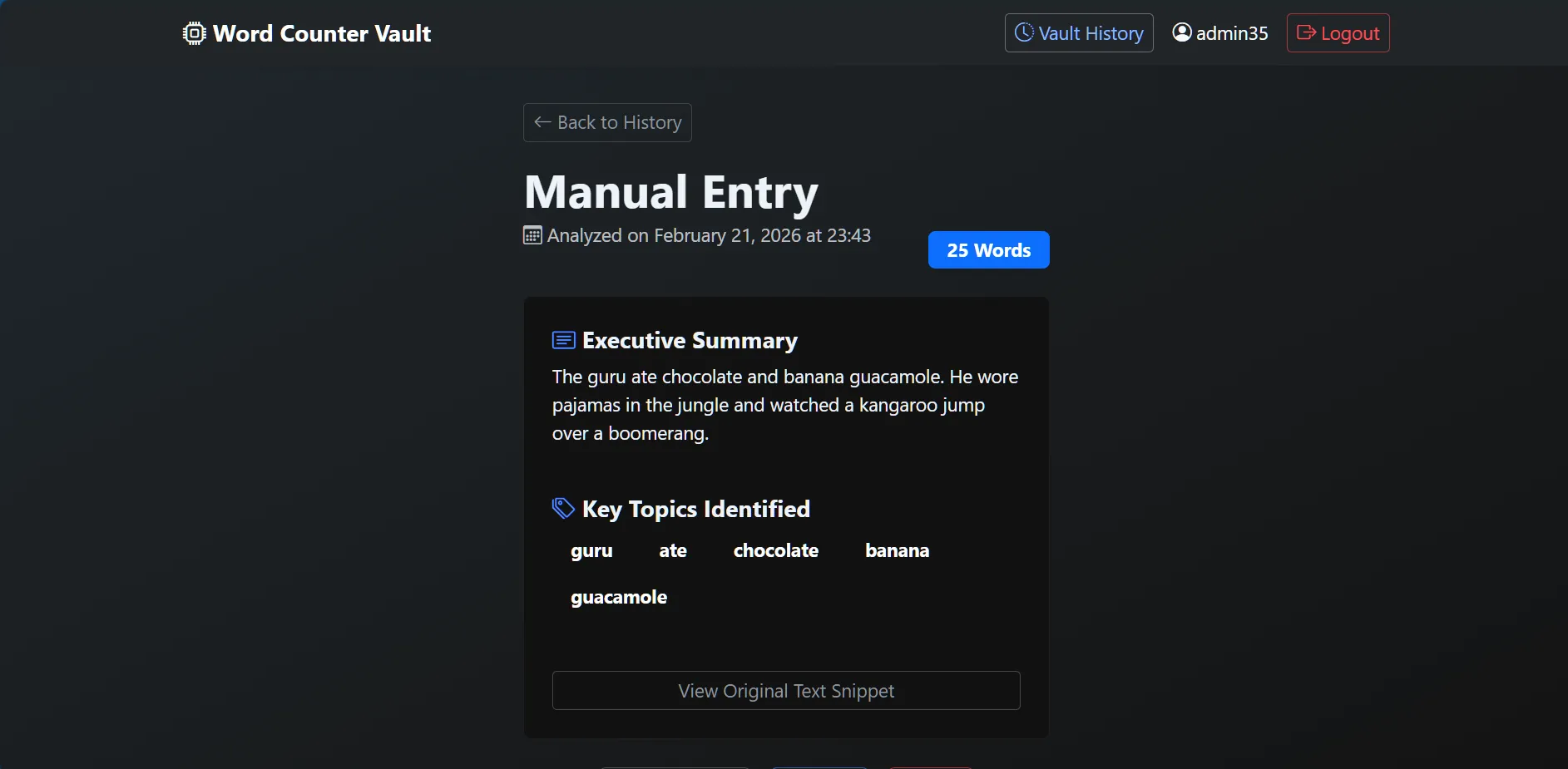
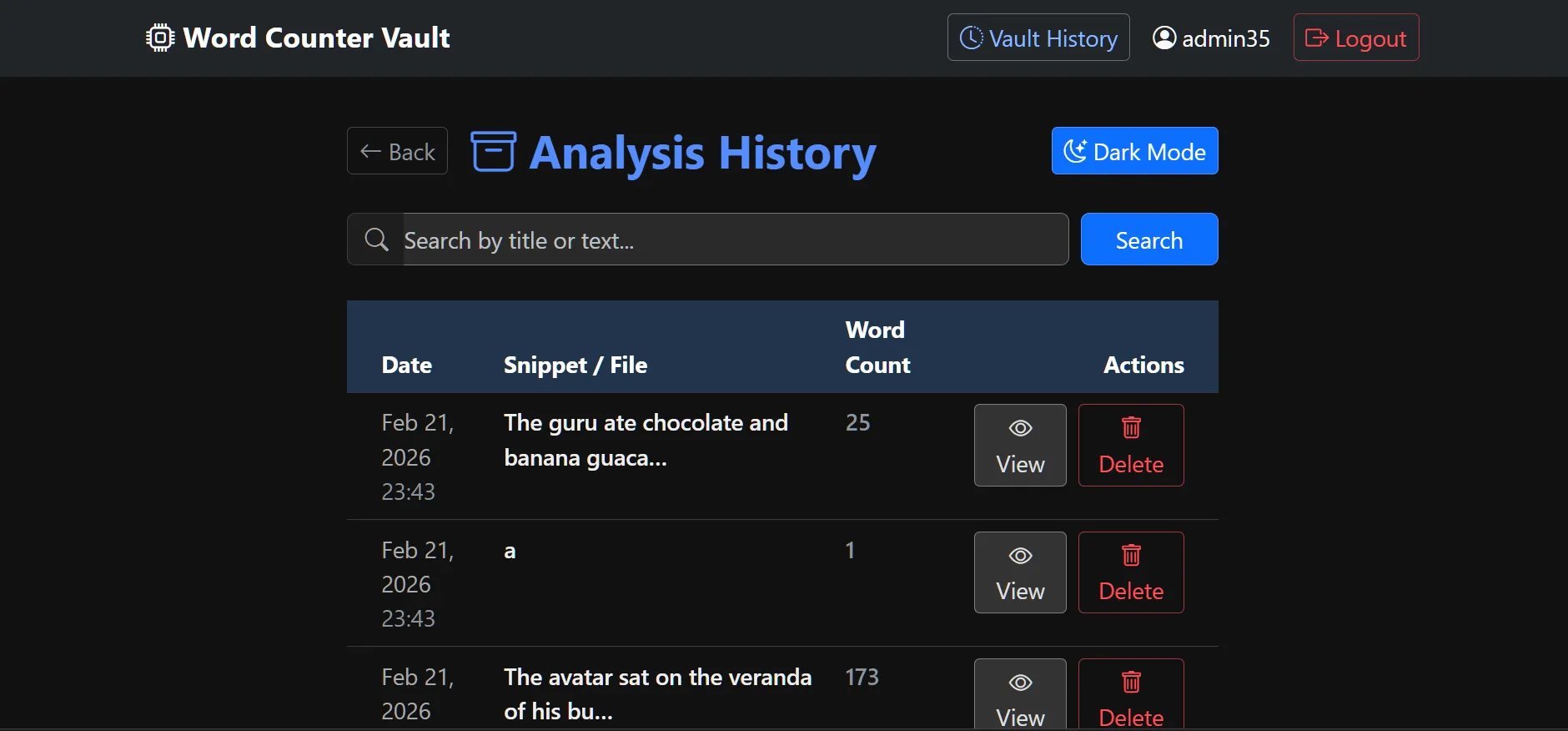
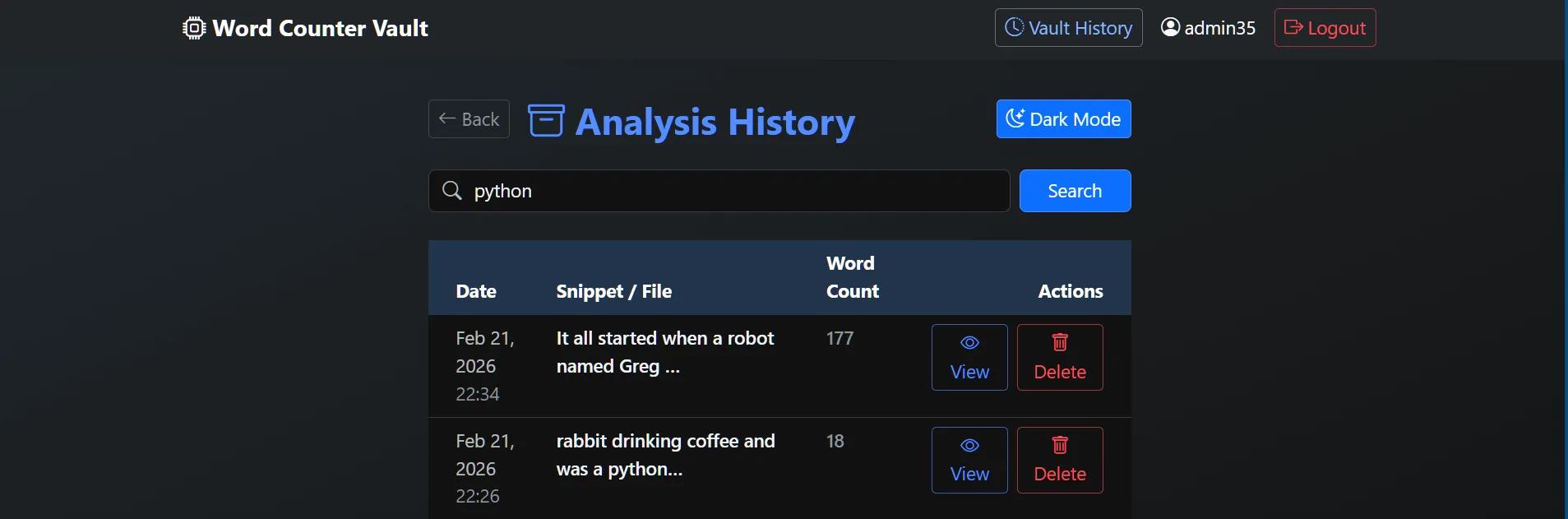
📸 Screenshots
See the full gallery here:
Click to expand screenshots



🛠️ Project Architecture
This project is divided into two main components to balance real-time user interaction with deep-dive analytical processing:
1. Interactive Analysis Dashboard (views.py & templates/)
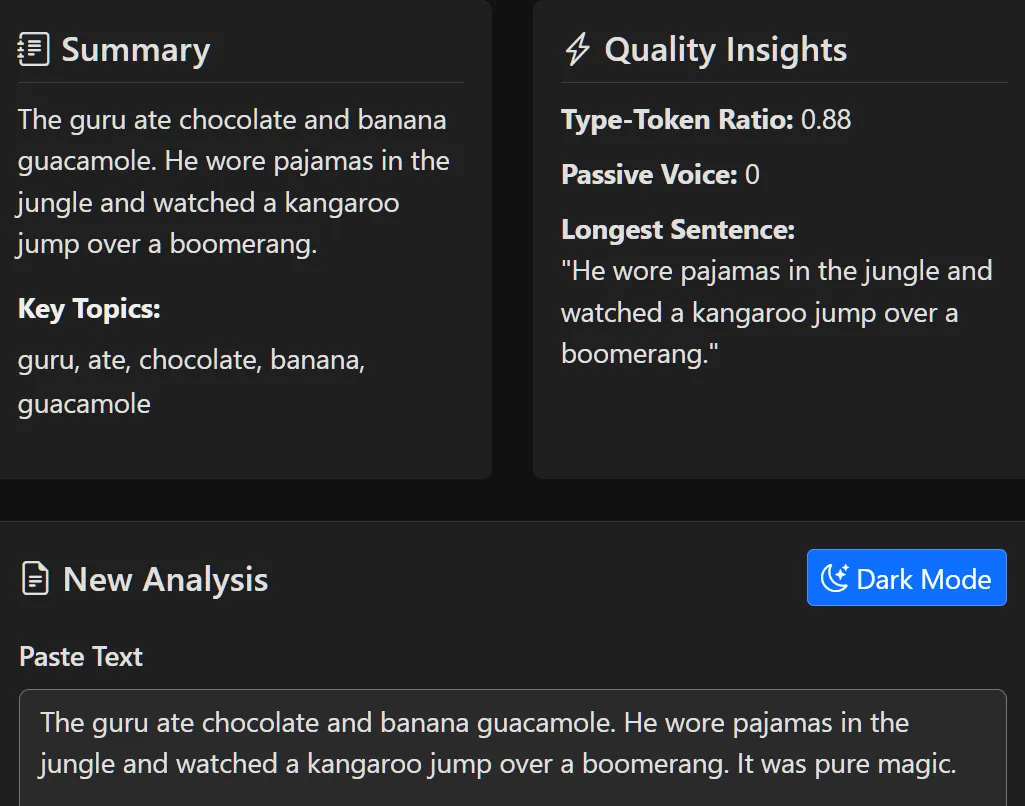
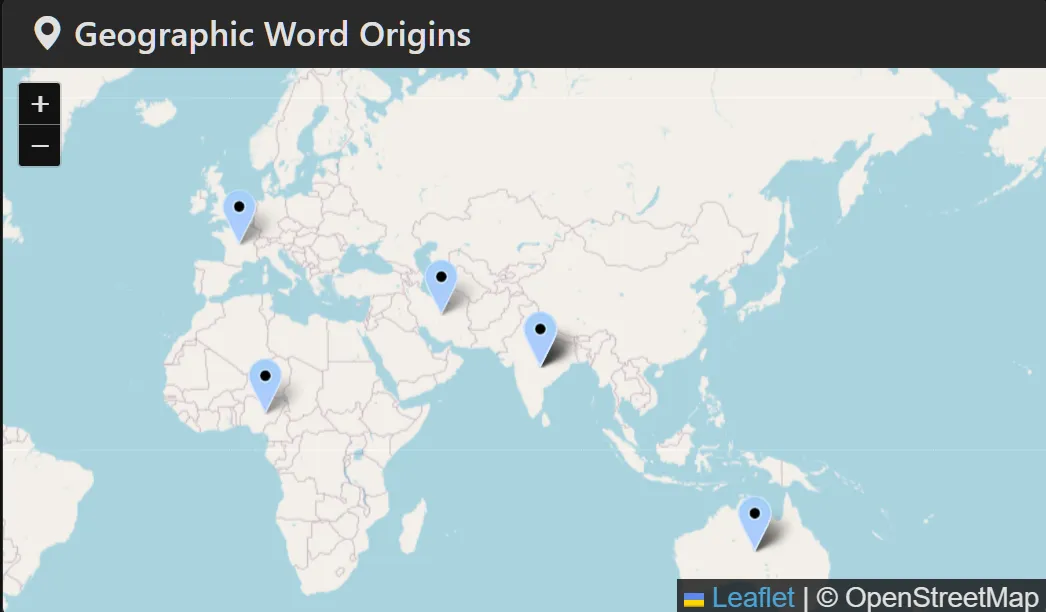
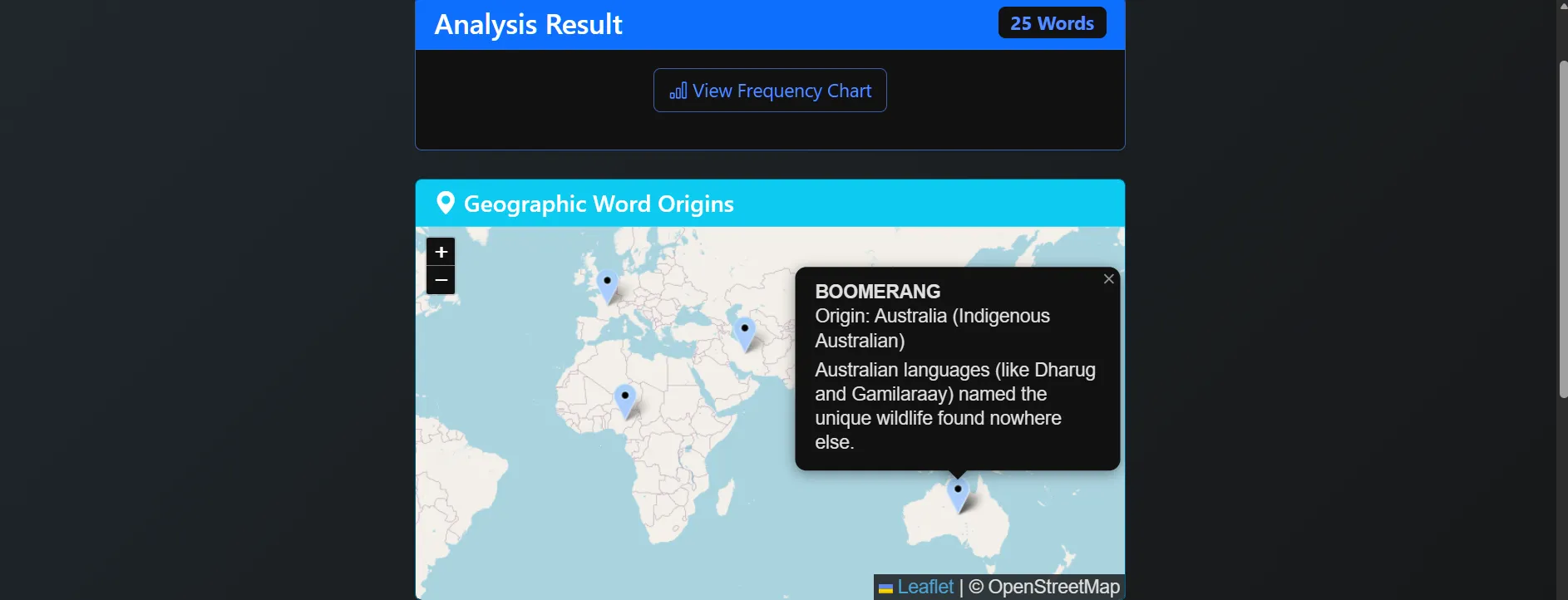
The "Frontend" logic of the project. It provides a real-time interface for users to explore their text data. * Dynamic Geospatial Mapping: Visualizes the "geographic DNA" of a text by pinpointing word origins across a global map using Folium. * Instant Linguistic KPIs: Calculates Lexical Diversity (TTR), Overused Words, and Passive Voice detection on the fly. * User Vault: A persistent history system allowing users to search, review, and manage their analysis records securely.
2. Forensic Reporting & Data Engine (services/ & models.py)
The "Analytical Backend." This handles the heavy lifting of data management and document generation. * Dual-State Storage: Manages persistent user history in SQLite while offloading high-speed etymological lookups to a DuckDB OLAP engine. * Global Etymology Pipeline: A custom ingestion layer that maps over 500+ words to global coordinates (Latin, Germanic, Arabic, Sanskrit, and more). * Automated Document Generation: Compiles findings into professional PDF reports (via WeasyPrint) and Word documents (python-docx) for offline review.
📁 File Structure
word_counter/settings.py: Core configuration for the Django environment.counter/views.py: Logic for text processing, regex normalization, and dashboard rendering.counter/services/seed_origins.py: Data pipeline script for ingesting the global word library.counter/services/word_data.json: The "Source of Truth" containing 500+ global etymology records.word_vault_analytics.duckdb: High-performance database for geospatial word lookups.
🧰 Tech Stack
- Python 3.10 (Development Environment)
- Django 5.2: For the web framework and user authentication.
- DuckDB: For high-performance, local analytical etymology queries.
- SQLite: For persistent user history and session management.
- Folium/Leaflet: For interactive geospatial mapping.
- WeasyPrint / python-docx: For automated forensic report creation.
- Regex: For high-speed text normalization and cleaning.
⚙️ Installation & Local Usage
To run this project locally:
1. Clone the repo: git clone https://github.com/reory/Word-Counter-Vault.git
2. Install dependencies: pip install -r requirements.txt
3. Seed the Global Vault: python -m counter.services.seed_origins
4. Launch the app: python manage.py runserver
🧪 Quality Assurance & Testing
This project implements a comprehensive automated testing suite using Pytest to ensure data integrity and security across the analytical pipeline.
Test Coverage:
- Linguistic Logic: Validates regex normalization, word frequency calculations, and lexical diversity metrics.
- Security & Permissions: Ensures strict object-level access control (e.g., users cannot view or delete others' analysis history).
- Service Layer & Mocking: Utilizes
pytest-mockto simulate DuckDB OLAP connections, allowing for high-speed testing without disk I/O dependency. - File Extraction: Verifies robust handling of
.txt,.pdf, and.docxuploads using Django'sSimpleUploadedFile.
Running Tests locally:
pytest
🙏 Acknowledgments
- Etymology Sources: Online Etymology Dictionary for root-word tracking.
- Community: Thanks to the Django and DuckDB communities for the robust library support.
🛣️ Roadmap
- [x] Core Architecture: Dual-Engine (Django + DuckDB) setup.
- [ ] Data Seeding: Integration with
Fakerfor large-scale stress testing. - [ ] Geospatial Mapping: Interactive etymology origins via Plotly/Mapbox.
- [x] Forensic Reporting: PDF/CSV export functionality for text analysis.
- [x] User Accounts: Private storage for linguistic history.
⚖️ License
This project is licensed under the MIT License - see the LICENSE file for details.
Built By Roy Peters 😁 ![]()